TEAM MEMBERS
- Ye Qi (yeq@andrew.cmu.edu)
- Yuhan Mao (yuhanm@andrew.cmu.edu)
SUMMARY
We implemented a parallel and distributed version of Latent Dirichlet allocation algorithm on multiple multi-core CPU machines using MPI and OpenMP. Our 32-core asynchronized master-worker implementation running on AWS (m4.16xlarge instance with the Intel Xeon E5-2686 v4 CPU) achieves a 28x speed-up over its 2-core baseline when testing on NYTime dataset, which consists of 1 million documents and 100 million terms.
BACKGROUND
Overview
Latent Dirichlet Allocation (LDA) [1] is the most commonly used topic modeling approach. While leveraging billions of documents and millions of topics drastically improves the expressiveness of the model, the massive collections challenge the scalability of the inference algorithm for LDA.
Below is the conventions used in this report.
| Symbol | Description | Range |
|---|---|---|
| N | Corpus size (number of all the terms) | 15M+ |
| W | Vocabulary size (number of distinct terms) | 15K+ |
| K | Number of latent topics | 10 - 3000 |
| D | Number of documents | 30K+ |
| T | Number of iterations | 1K+ |
Input and Output
The brief idea of Collapsed Gibbs sampling (CGS), known as the solver for LDA, is shown in the graphs [2] as follows :
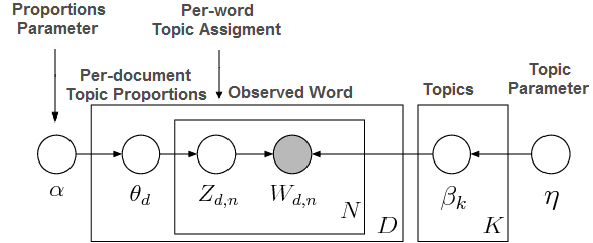
This unsupervised generative algorithm starts off by taking a collection of documents as input, in which each document is represented as a stream of word tokens. The output is a word-topic distribution table and a document-topic distribution table that could be used to predict the topic of a given document.
Key Data Structure
The data structure involved here are fairly straightforward:
- Document-topic distribution table: a two-dimensional array of size DK
- Document-word-topic assignment table: a two-dimensional array of size DW
- Word-topic distribution table: a two-dimensional array of size WK
- Topic distribution table: a one-dimensional array of size K
According to the common range of each parameter, the topic distribution table is trivial to store. It’s the document-topic distribution and the document-word-topic assignment table, as well as the word-topic distribution table the real killers to traverse and to communicate with. The upper bound of W is limited by the Zipf’s Law in English languages. However, D could reach a much higher value, especially in large-scale data analysis.
Operations
The algorithm essentially iterates over all the word occurrences in all the documents and updates the word-topic, document-topic and topic count tables in the meanwhile. The pseudocode is as follows:
for d in document collection:
for w in d:
sample t ~ multinomial(1/K)
stored t to document-word-topic assignment table
increment corresponding entries of t in the word-topic, document-topic and topic count tables
while not converge and t <= T:
for d in document collection:
for w in document:
get t from the document-word-topic assignment table
decrement corresponding entries of t in the word-topic, document-topic and topic count tables
calculate posterior p over topic
sample t' ~ multinomial(p)
increment corresponding entries of t' in the word-topic, document-topic and topic count tables
Technical Challenges
The largest challenge is that Gibbs sampling by definition is a strictly sequential algorithm in that each update depends on previous updates. In another word, the topic assignment of word w in document d cannot be performed concurrently with that of word w’ in document d’.
Workload and Dependencies
As we noticed that the topic assignment of a word depends more on the topic of other words in the same documents (n_d,k) than those elsewhere in the corpus (word-topic distribution n_k,w and topic distribution n_k) because these probabilities, as calculated following, only change slowly.
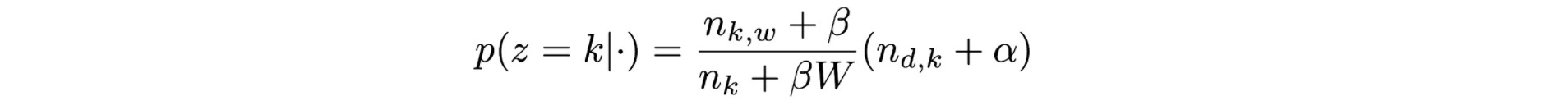
Thus, it’s possible to release the strict dependency and approximate this sampling process by randomly assigning documents to p processors, then have each processor performed local sampling process and merge updates after a period of time. Newman, et al [3] have already investigated the effects of deferred update, and they found it will net correctness of the Gibbs sampling, but only results in slightly slower convergence.
Locality Analysis
Identifying locality is crucial in a parallel program. However, the randomicity of Gibbs sampling prevents us from utilizing SIMD operations or any elaborate caching strategies.
The sampling for a single word w takes O(K) time, but the actual time could not be easily predicted. This divergence in instruction stream results in weak SIMD utilization.
As for data structure access pattern, both word-topic table and document-topic table are accessed row by row. The columns inside each row are accessed randomly submit to a multinomial distribution. Both two tables could easily exceed than 20 MB. Caching might be useless for such large tables with pure sequential access pattern in rows and pure random access pattern in columns.
If the vocabulary size is sufficiently greater than the number of processors, the probability that two processors access the same word entry is small, so false sharing is not likely to happen in our case.
Compuationally Expensive Part
This algorithm is computationally intensive when K is not too small. For each inner loop, there are 6 loads and stores and 6 + 6K + O(K) computations. And a single loop will be repeated for NT times.
Parallelism Description
In this project, we leveraged the data-parallel model to partition the document collection into p subsets and had them sent to p workers. A worker could be either a process on a machine or a machine on a cluster. p workers could perform Gibbs sampling concurrently. Since document-word-topic assignment table and document-topic distribution table are only related to the documents lied on this worker, there’s no need to exchange them. Topic distribution table and word-topic distribution table, however, should be considered shared across all the workers and require synchronization.
As a result,the time complexity and space complexity become:
| Sequential | Parallel | |
|---|---|---|
| Space | N + K (D + W) | (N + KD) / P + KW |
| Time | NK | NK / P + KW + C |
KW + C is considered the communication overhead. We tried our best efforts to minimize this overhead while maintaining reasonable converge rate.
APPROACH
Technologies Used
MPI: Message Passing Interface is a standardized and portable message-passing system designed by a group of researchers from academia and industry to function on a wide variety of parallel computing architectures. The standard defines the syntax and semantics of a core of library routines useful to a wide range of users writing portable message-passing programs in C, C++, and Fortran.
Problem Mapping
First, we map a worker or master to a process.
A worker -> a process who does the real work in the LDA algorithm we talked above – Gibbs Sampling; A master -> a process to coordinate the communication amongst workers, maintaining the per-word topic assignment and topic parameter in the up chart as well as calculate the log-likelihood after each iteration to evaluate the convergence of the algorithm.
Since the process can be assigned to the same machine or different machines and so as MPI, our algorithm can be easily distributed to multiple machines with minor or no modification. Second, we separate the entire documents randomly to all the workers. In each iteration, the worker performs Gibbs sampling on their local copy of the parameter tables and records the updates. They Synchronize these local parameters tables with the master every particular time.
Approximation Algorithm
The algorithm has a strict-sequential dependency for every step of the Gibbs Sampling. However, due to the size of the table space and the characteristic of the algorithm, there is a very low chance of conflict. And more importantly, the conflict of the updates may not impact the correctness of the algorithm. Because the sampling itself is a random process, staleness of the parameters only leads to slower convergence. This effect has even trial influence when there is a large topic number (e.g. 1000), so we decide to make it hard for our algorithm and limit our experiments to 20 topics.
Proposed Method
We implemented the distributed and parallel version of LDA from scratch in C++ with the support of MPI. The following graph scatches our pipeline.
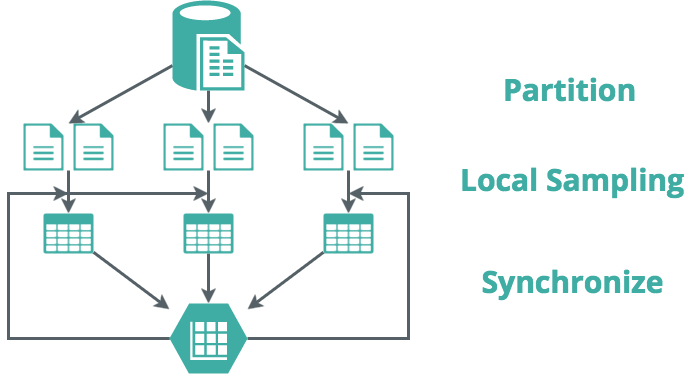
The synchronization is carried out at every checkpoint. Our program supports setting up the checkpoint after processing a certain amount of documents. It could be within the same iteration (i.e. every 1/10 iteration) or after several iterations. This is a parameter to be tuned to achieve a trade-off between efficiency and convergence.
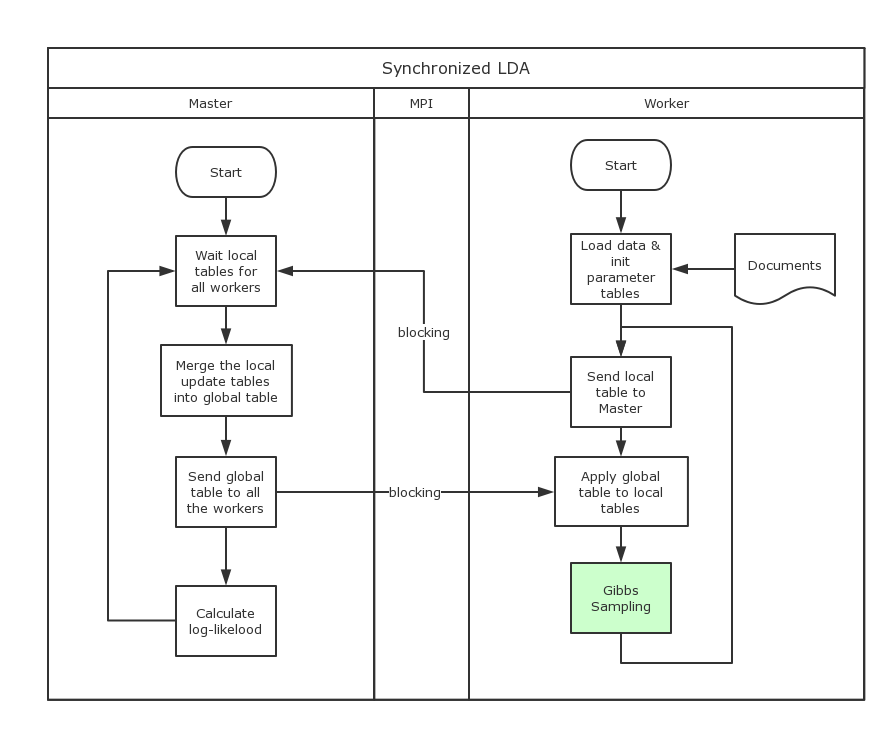
Synchronized LDA
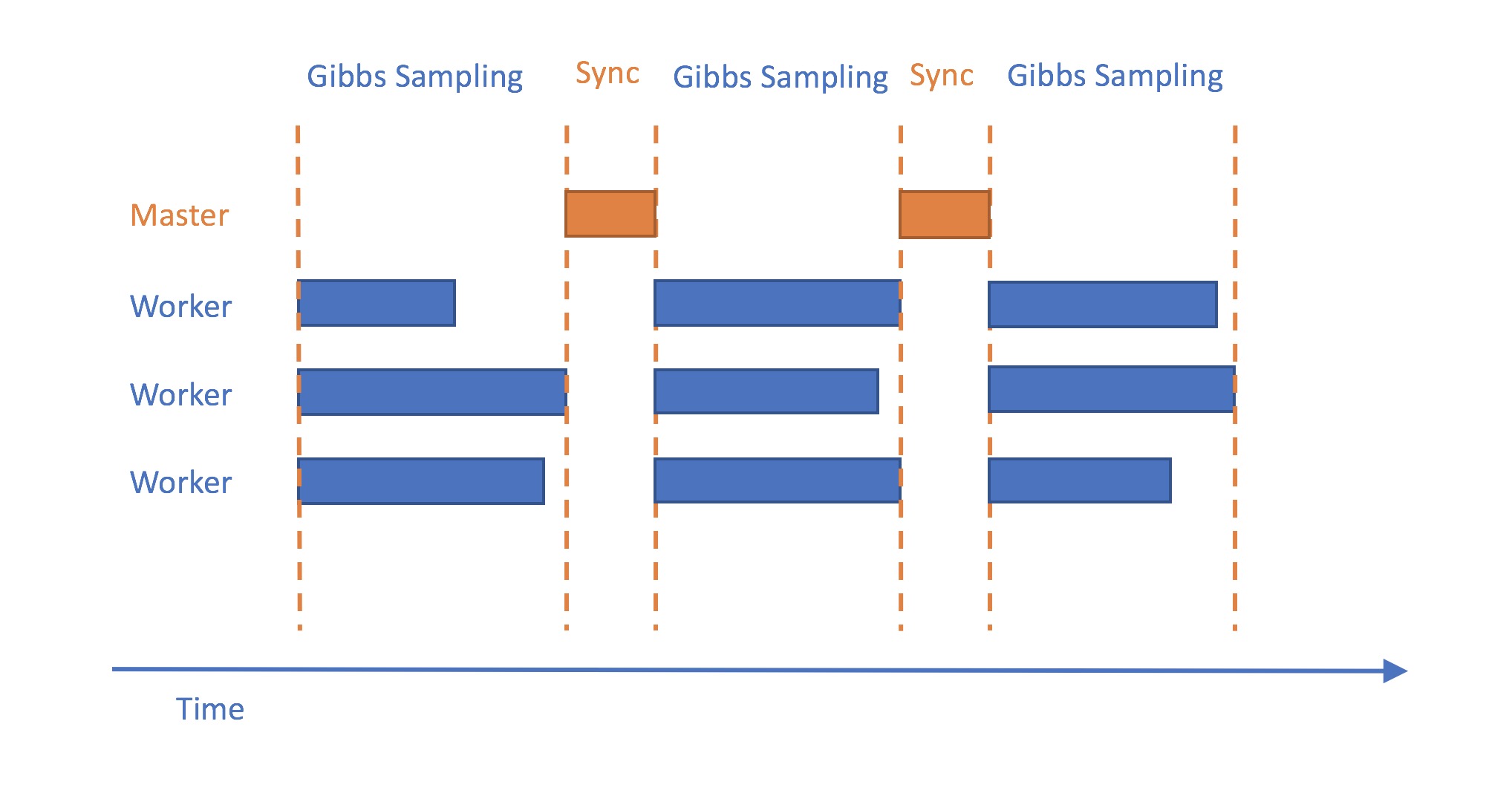
This is a simple algorithm proposed by Newman. In this setting, every worker, along with the master synchronizes their parameters at every checkpoint. When they are sending messages, all the workers are blocked until all of them have the most up-to-dated parameter tables back from the master. Below is the chart illustrating this workflow:
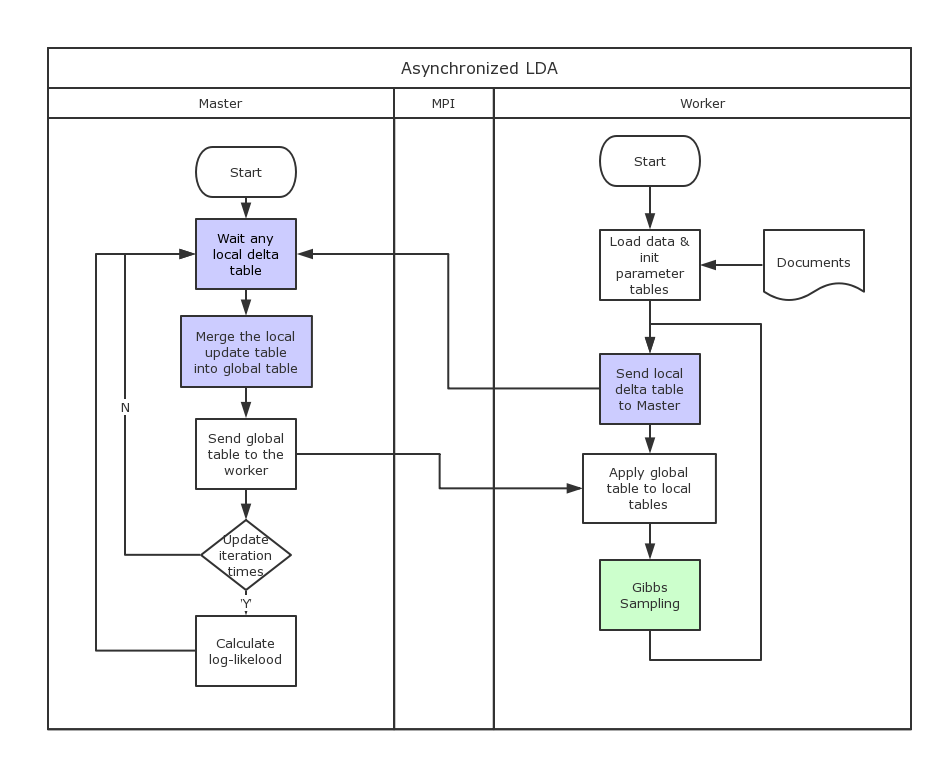
Asynchronized LDA
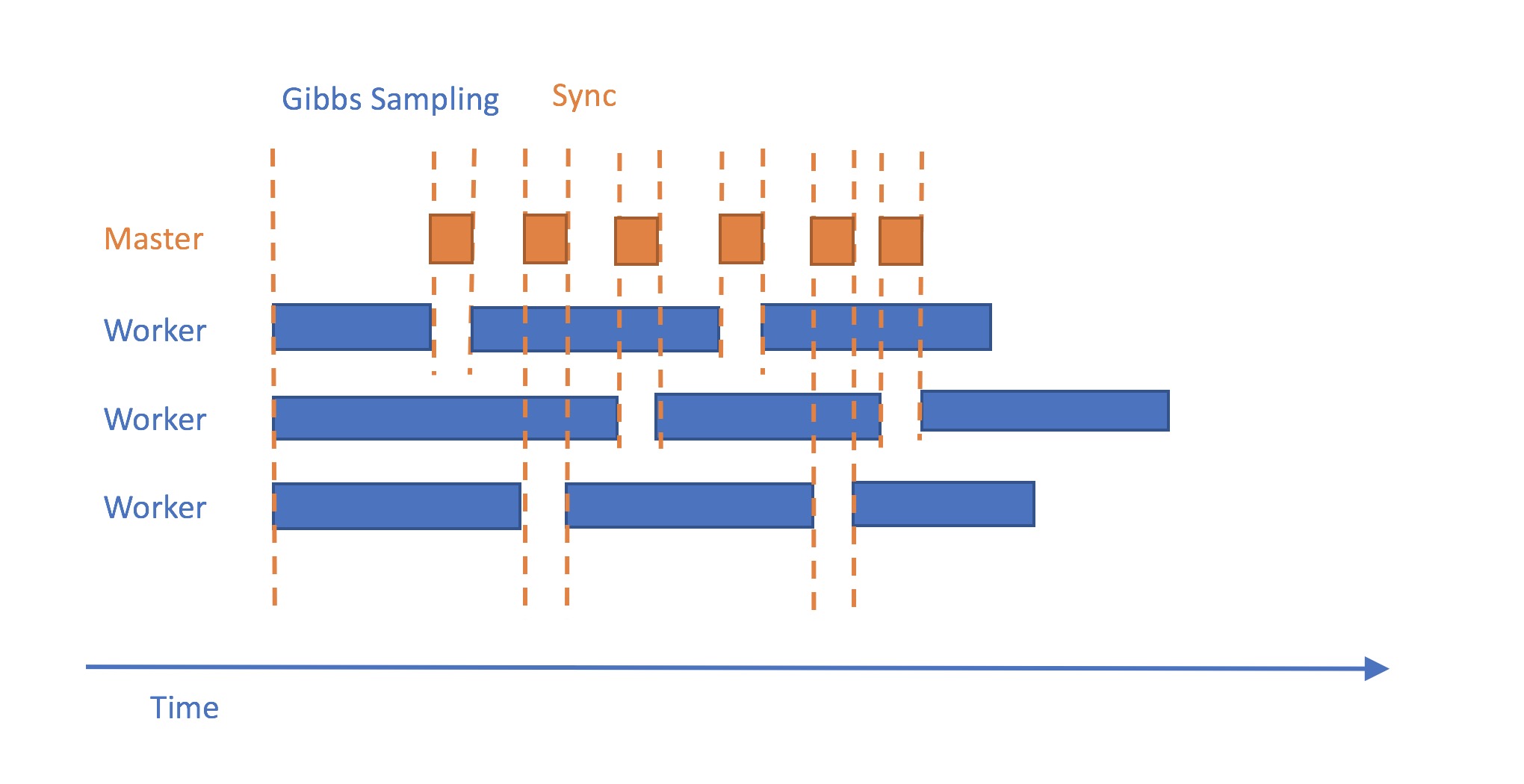
The bottleneck for the synchronized LDA is the synchronization. As the chart shown above, all the workers need to wait the slowest worker to finish its job before stepping into next stage. Because the variation of the machine status and the impossible of distributing work absolute even, some time are wasted. Things become even worse when scaling up, the slowest worker will encumber all the workers. The solution here is to perform the communication whenever the worker reach its own check point (e.g. perform Gibbs Sampling on a certain amount of documents) it will communicate with the master to perform its update to the delta table and acquiring the most up-to-dated global table. However, because the master no longer knows the worker’s state or which iteration the worker is current at, merging parameter tables can only be achieved with delta table (i.e. the change of the parameters table since last communication). Although the up-to-dated global parameter table still can be transferred back as the synchronized version. Thus, compared to synchronized version, workers need to do a little bit extra work – updating both parameter tables and delta table during the Gibbs Sampling.
Unsuccessful Trials (A lot of!!!)
Delta Table
We attempted to use a delta table to communicate with workers and master, i.e. workers send their delta table since the last synchronization to the master and master merges all the delta tables of the workers and send the merged(global) one back to all the workers. The advantages of this approach are the delta table can be compressed to reduce the message size for sparse delta parameters tables. However, it needs an extra iteration of the word topic table to apply the global update to the local parameters table when the worker receives the global delta table.
Sparse Matrix Representation
While frequent communications maybe expected sometimes (when checkpoint = every 100 documents), we thought it might be better to transfer only the updated indices instead of the raw word topic tables. We utilized an unordered hashmap to store the updates between each two iterations. The higher 24 bits of the key represents the word while the low 8 bits represents the topic. The value denotes the corresponding word-topic count. This is designed to reduce the communication overhead by compressing the delta table to a smaller size.
The performance is not ideal because of the power low between corpus size and vocabulary, which is to say even the number of documents is not large, the probability that we see most of the words is still pretty high. When the number of topics is not large, the merged word-topic table is still rather dense because the tables from different workers vary a lot since they are generated from different datasets and parameters. In our setting (K = 20), the overhead for marshaling and unmarshalling counteracts the time saved in transferring data.
This trick hopefully works well for larger topic number (K >= 1000). However, larger topic number requires much more computations during each iteration. The machines available for us cannot be used to conduct long-term training.
Non-blocking Communication
We also attempted to completely eliminate the blocking window for any forms of synchronization when receiving parameter update tables from each worker. In another word, we expect that workers could immediately return without waiting for the master’s response. The original intention for this approach is to hide the latency of the long synchronization that requires every worker to participate. I.e. instead of block waiting for the master to process the merge and send the global table back, worker can still process the Gibbs Sampling with its current parameter table. But the price we pay for this is we need another piece of memory to store the incoming global tables and has to check if the incoming tables have been received regularly. Again, this methods should provide better performance for larger word topic table (larger K and vocabulary size) since the communication time is longer and worth to be hidden, but has trivial impact on our current settings.
RESULTS AND DISCUSSION
Performance Measurement
We use Log-likelihood to measure the convergence of the LDA. Since the algorithm is exactly the same as the sequential one, and it always converges to the same place, we focus on improving the speed rather than something else(e.g. accuracy at the converge point).
Experimental Setup
The sanity check is against 20news Dataset [6] which includes 18,774 documents with a vocabulary size of 60,056.
The thorough experiments are performed on NYTimes corpus from UCI Machine Learning Repository[7], which consists of 102,660 documents and a vocabulary size of 299,752. The total number of word occurences is around 100,000,000.
Other setthings for Gibbs sampling are lists as follow:
| Parameter | Value |
|---|---|
| K | 20 |
| α | 0.1 |
| β | 0.1 |
| T | 100 |
| checkpoint (synchronize every) | 10,000 |
K was set to a relatively small number because 1) we want to explore the parallel Gibbs sampling on rather dense word-topic tables; 2) limit training time so that we could produce comprehensive evaluation.
We ran both the synchronized and asynchrnoized version of LDA program using from 2 cores up to 16 cores on GHC machines, which has 8 physical cores (2 hyper-threads) 3.2 GHz Intel Core i7 processors and the L3 cache size is 20MB.
Though the program also supports distribution across machines on the cluster, we chose to do our experiments only using multi-core configurations because the dataset is not large enough to let the speedup from parallelism overwhelm the latency of transferring large buffer using network.
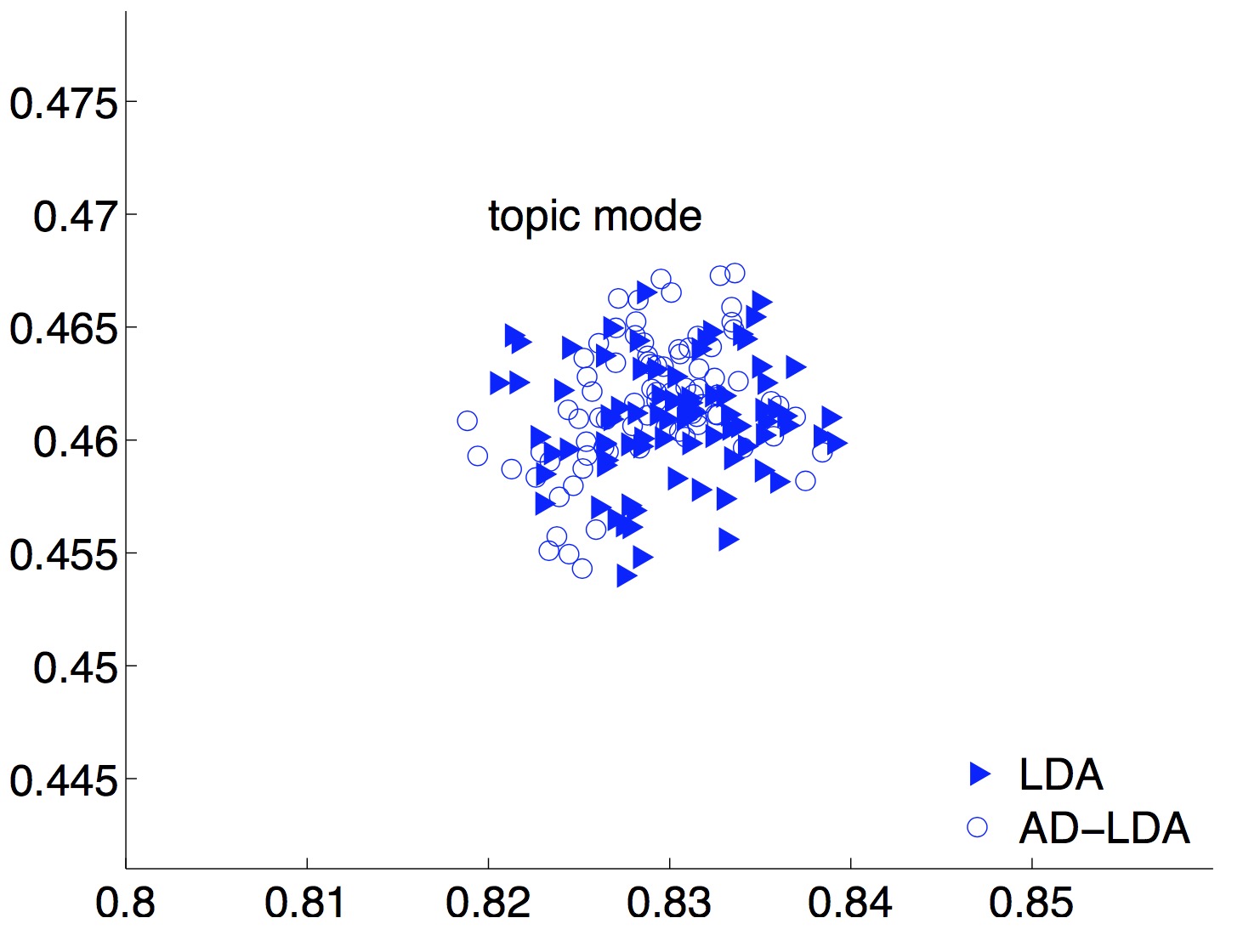
Convergence
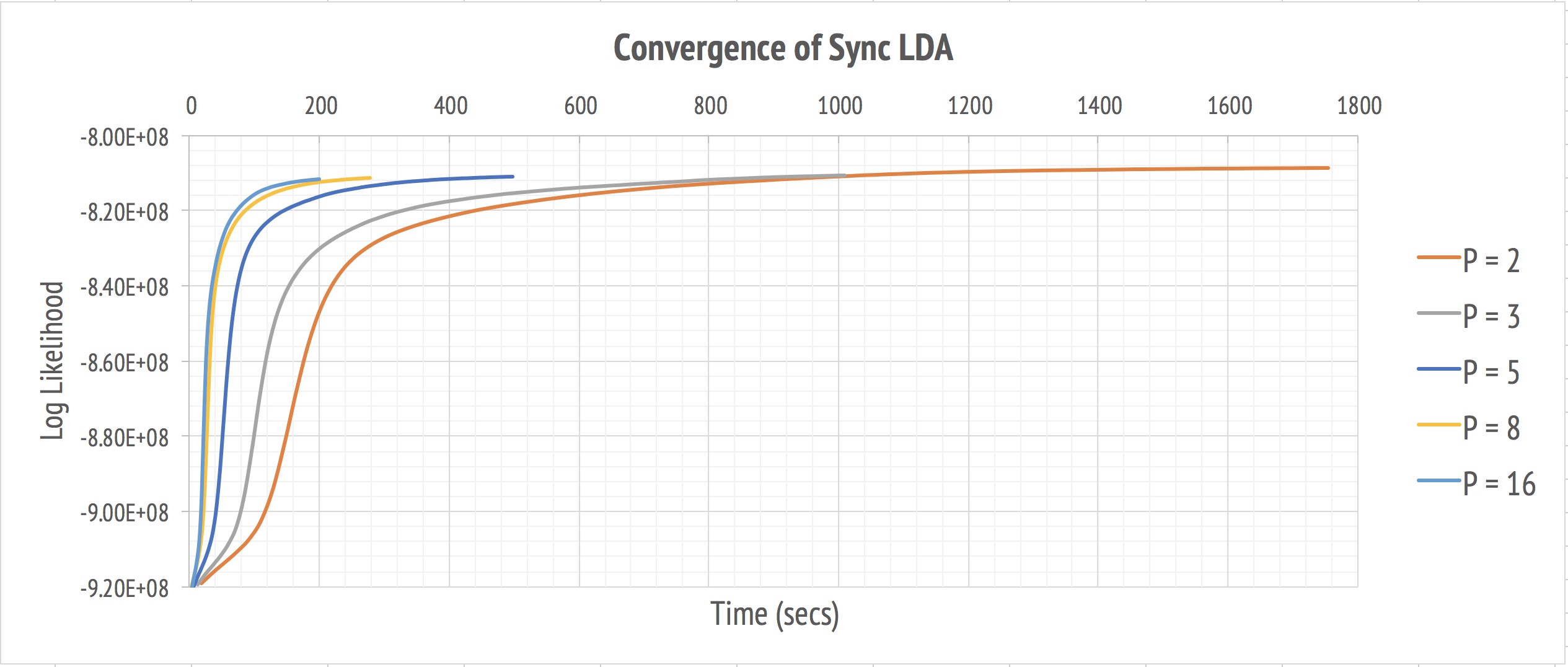
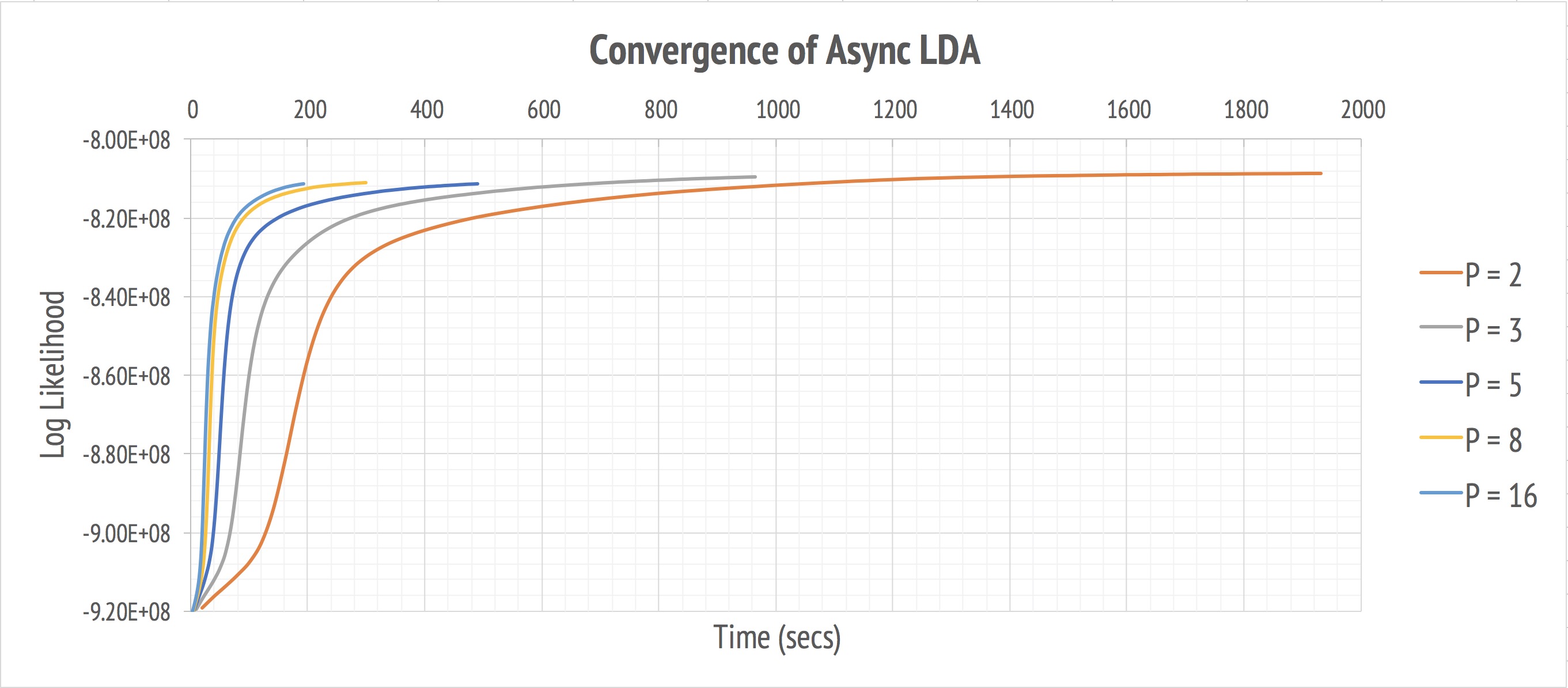
The two pictures above display the convergence behavior of our program. Both synchronized and asynchronized implementation eventually converge to similar likelihood as the number of workers goes up. It demonstrates that this parallel approximation to true Gibbs sampling produces comparable result but much faster when leveraging more resources. The asynchronized version is slightly faster.
Scalability
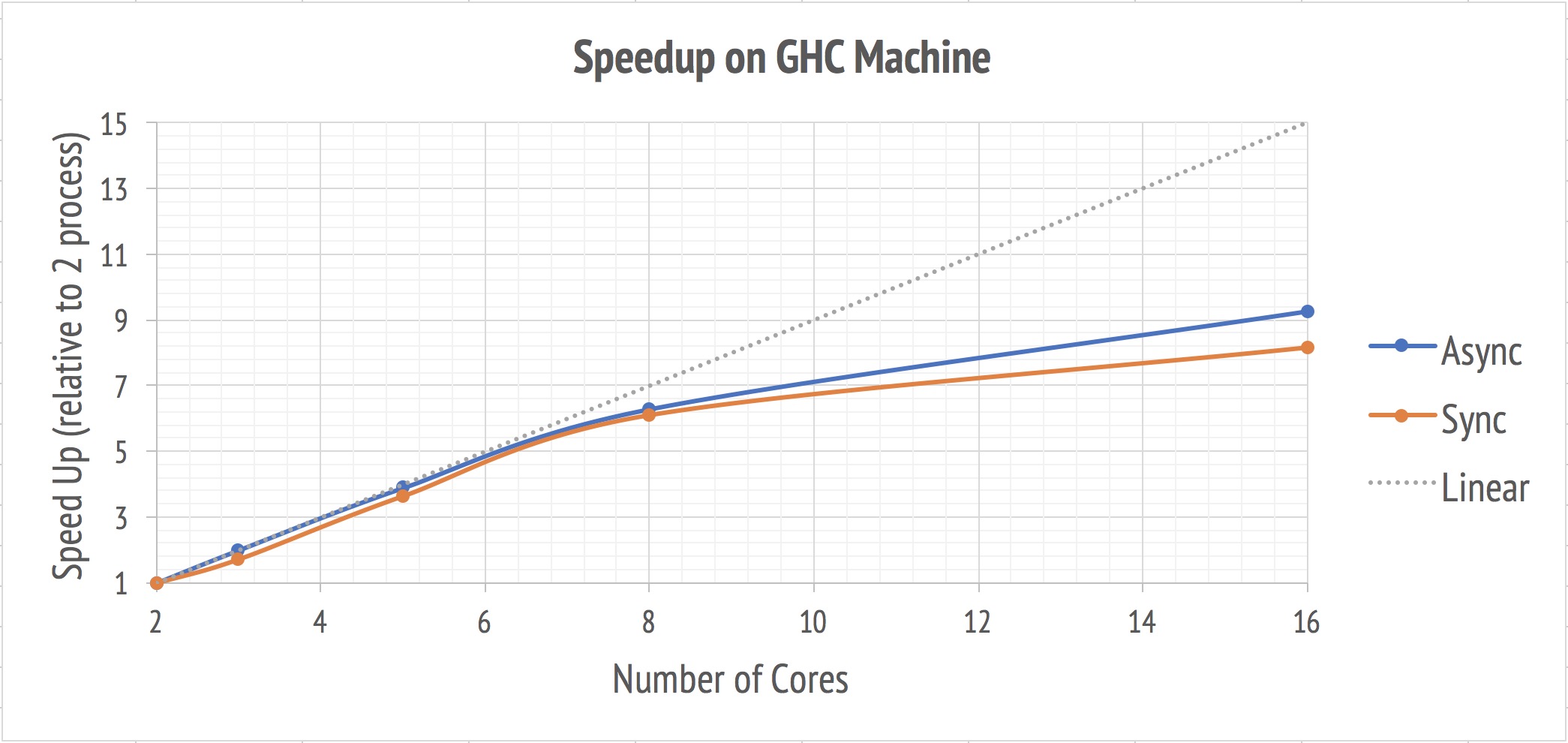
While the accuracy of the program has been proved by previous graphs, we moves on to investigate the scalability of this algorithm. The speed up is calculated relative to the total time of running 100 iterations using 2 processes. We set the baseline as 2 cores because the asynchronized version requires an additional master.
As depicted in the plot, there’s a near-linear speedup before the number of processes approachs 8. The possible explanation for this phenomenon is the physical limitation of the GHC machines. As the number of processes surpasses 8, the process starts to make use of hyper-threading. However, as you can see, the performance of a hyper-threadig core can not achieve the same performance as a complete physical core.
While the program was running, we profiled the system resourse usage by looking at the CPU utilization. It’s around 103% when we were running on 8 processes but only 70%-80% when 16 processes were up.
Communication Overhead
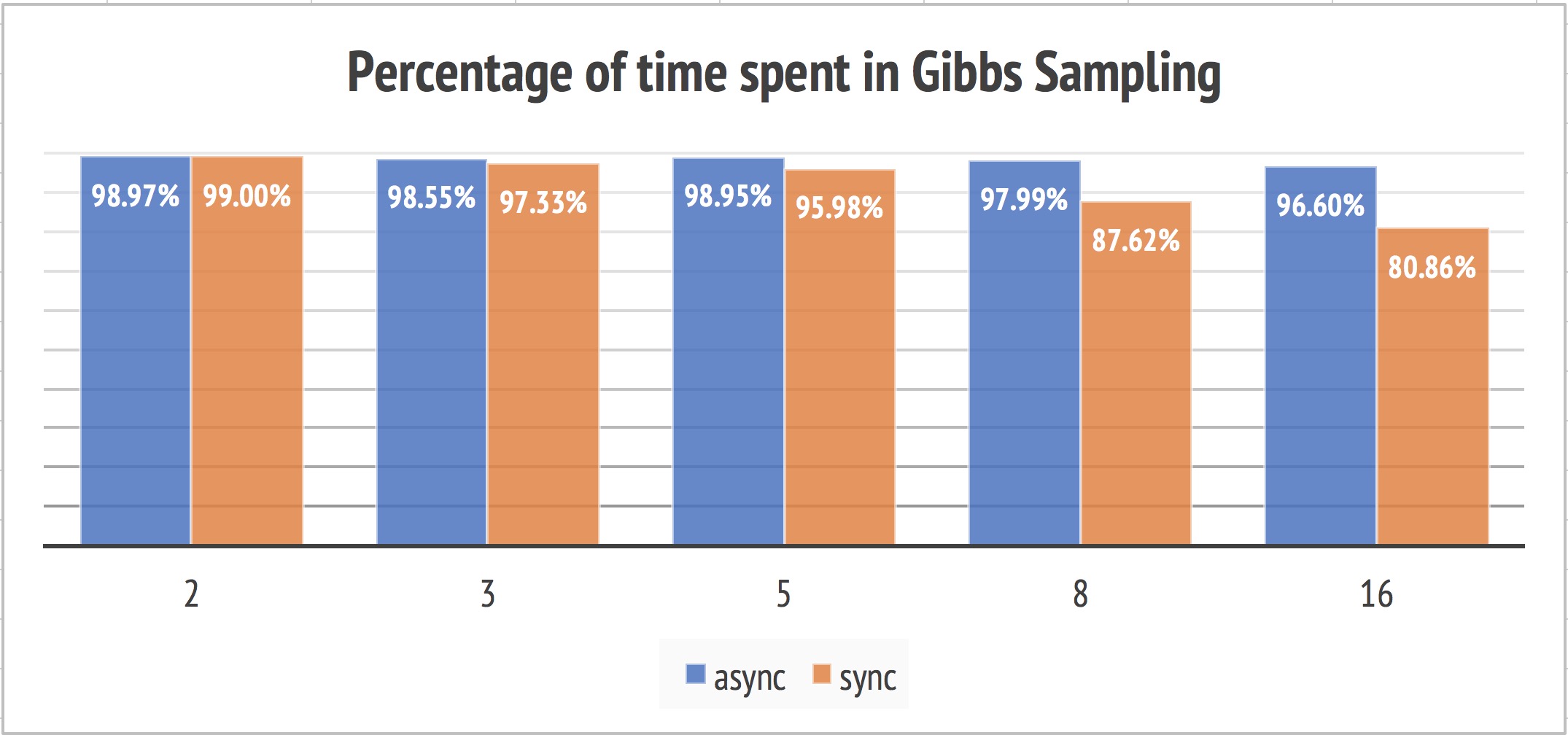
We broken the execution time of our problem into communication time and Gibbs sampling time to conduct a deeper analysis on its performance. The hypothesis here is that the larger percentage of time spent in Gibbs sampling, the more scalable the algorithm is. It’s because the program spent less time in communication than doing real useful computations. Our asynchronized implementation exerts much higher percentage as opposed to its synchronized counterparts.
Additional Experiments: AWS
As the reasoning illustrated in the previous section, we decided to try our algorithm on a larger machine to see if our guess holds. We tried submitted multiple time on the Latedays cluster but unfortunately for some reason our jobs were killed before we can get enough experiment results to do the further analysis. We turned to AWS for help. Spent some money, we launched a m4.16xlarge instance with the Intel Xeon E5-2686 v4 CPU. AWS provided 64 vCPU for this type of instance.
Beside the change of the machine, we also reduced the communication times by increasing the tunable parameter documents per synchronization from 10000 to 50000. One reason is the observation of the increasing communication time ratio when the number of the workers increases. Another reason is in the previous experiments, our algorithm with multiple workers convergences as well as a single worker (equivalent to sequential LDA). So to make it even more scalable, we can sacrifice some convergence along the way.
Other setthings for Gibbs sampling are lists as follow:
| Parameter | Value |
|---|---|
| K | 20 |
| α | 0.1 |
| β | 0.1 |
| checkpoint (synchronize every) | 50,000 |
Here is the results we have:
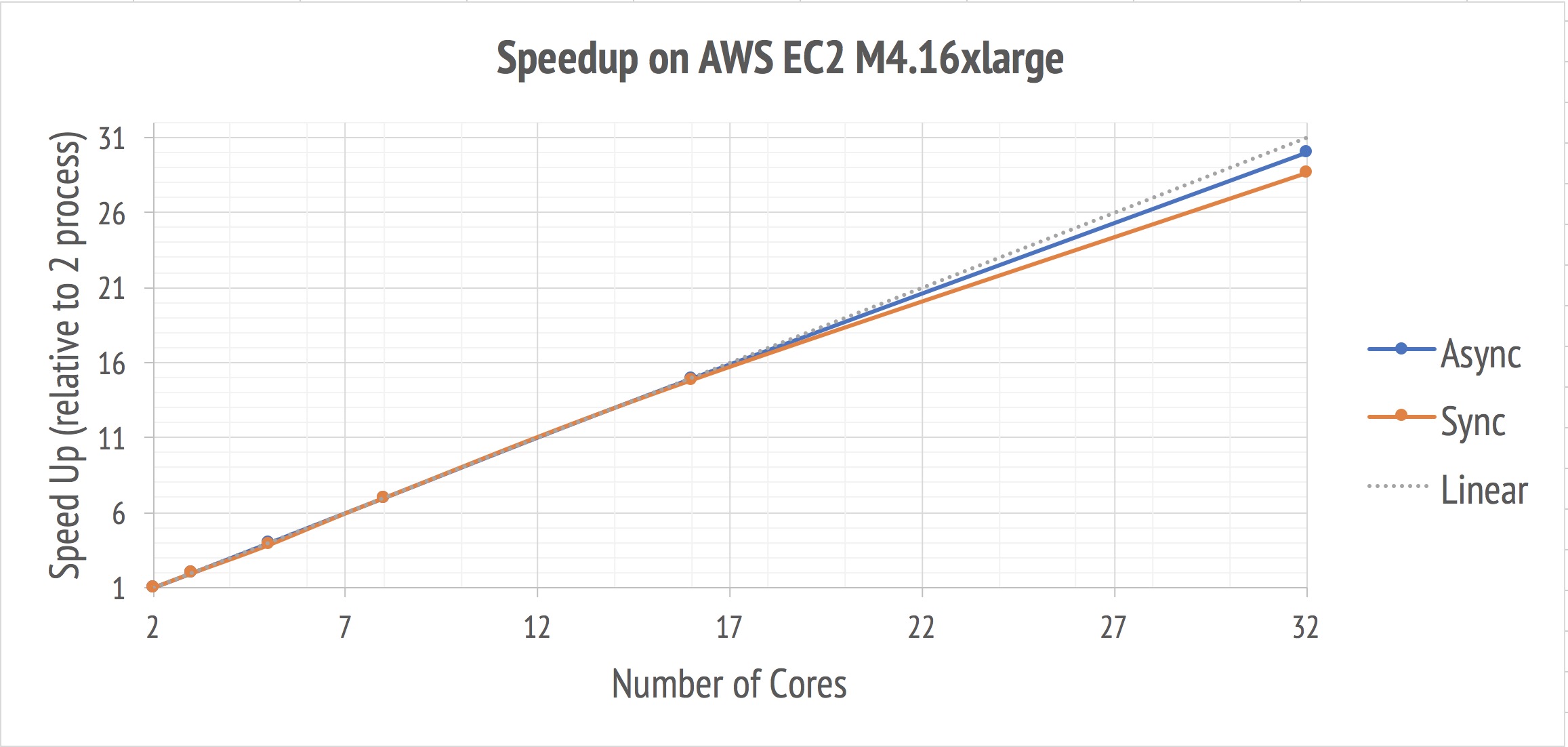
By decreasing times of the synchronization, both the synchronized and asynchronized version can achieve a even better speedup compared to the previous experiment with 16 cores or less, which is a almost linear speedup. Besides, the speedup achieved on AWS on 16 cores compared to that on the GHC machine provided our guess that the hyper-threading is the reason for the unsatisfying performance for 16 workers on GHC machine.
And still, when scaling up, asychronized version outperforms the synchronized one because it requires less synchronization time and their synchronization time will not increases with the increasing of the number of the workers.
Future Work
-
From our observation, stale parameters influence influences more on the initiate stage of the Gibbs Sampling because the parameter tables change much more at the beginning and reach to a stable stage afterwords. Thus, a potential optimization would be decrease the communication frequency over the time to achieve a higher speedup.
-
For non-blocking communication mentioned in previous section, instead of clear the memory after each communication, it is possible to use the pointer-swap trick to avoid the unnecessary memory operation. Though every worker still need extra space to store a copy of the word topic table.
WORK BY EACH STUDENT
Equal work was performed by both project members.
Yuhan implemented the first version sequential version of LDA as the baseline. Ye referred to a lot of related papers to figure out the direction and did the configuration of run the MPI on both GHC as well as Latedays. And together, we finished our first version of the synchronized LDA using MPI.
While the first experiment turned not satisfying, we worked together to optimize and debug our code. Ye tried the sparse matrix and Yuhan adjusted the synchronized version to asynchronized one. After the coding part is done ,we ran our experiments, did the analysis and wrote the report together.
Reference
[1] Blei, D. M., Ng, A. Y., & Jordan, M. I. (2003). Latent dirichlet allocation. Journal of machine Learning research, 3(Jan), 993-1022.
[2] Abdullah Alfadda. (2014). Topic Modeling For Wikipadia Pages. Spring 2014 ECE 6504 Probabilistic Graphical Models: Class Project Virginia Tech
[3] Newman, D., Asuncion, A., Smyth, P., & Welling, M. (2009). Distributed algorithms for topic models. Journal of Machine Learning Research, 10(Aug), 1801-1828.
[4] Yu, H. F., Hsieh, C. J., Yun, H., Vishwanathan, S. V. N., & Dhillon, I. S. (2015, May). A scalable asynchronous distributed algorithm for topic modeling. In Proceedings of the 24th International Conference on World Wide Web (pp. 1340-1350). ACM.
[5] Chen, J., Li, K., Zhu, J., & Chen, W. (2016). WarpLDA: a cache efficient O (1) algorithm for latent dirichlet allocation. Proceedings of the VLDB Endowment, 9(10), 744-755.
[6] https://www.open-mpi.org/
[7] http://qwone.com/~jason/20Newsgroups/
[7] https://archive.ics.uci.edu/ml/datasets/bag+of+words